
Repository in Domain Driven Design
Oct 25, 2020

Enterprise applications often have complex data which need to persist. Data persistence has been a challenging issue in software production. Having an appropriate data persistent mechanism could be one of some factors which leads to having a successful software product. There are some design patterns related to data persistent, in this article I will try to describe some of them focusing on Repository one.
Repository Design Pattern mostly lives in the context of Domain Driven Design in collaboration with some architectural patterns like Layered Architecture, Domain Models, Service Layer, Data Mapper, Unit of Work which will be described briefly to have common understanding of these patterns.
Domain Driven Design
Domain Driven Design (DDD) is an approach to developing software for complex needs by deeply connecting the implementation to an evolving model of the core business concepts. The term was coined by Eric Evans in his book of the same title. Context, Domain, Model, Ubiquitous Language are basic concepts in DDD.
Layered Architecture
An application has some components that perform specific tasks. Layered Architecture organizes these components in a level that components with specific concern are in the same layer. For instance, the presentation layer consists of all components which build the user-interface, the persistent layer is a collection of components that perform data persistence and so on. Layers communicate with each other in a certain way, the structure of architecture defines the direction of communication between layers.
Domain Models
Martin Fowler in his book Patterns of Enterprise Application Architecture describes three patterns to organizing domain logic: Transaction Script, Domain Model and Table Module. The Domain Model is what we are interested in, which is classes for nouns in the domain. For instance, Customer is an Entity in a domain model in an ordering system. Domain Model should handle all data and business related to its concept.
Service Layer
Defines an application’s boundary with a layer of services that establishes a set of available operations and coordinates the application’s response in each operation.
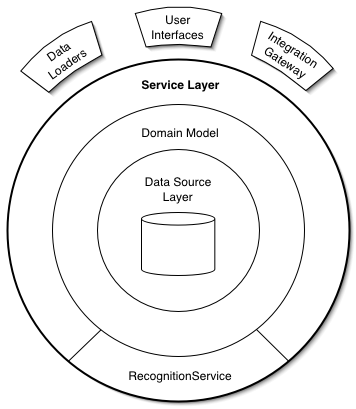
Service Layer is where the application’s operations take place. This layer encapsulates application business logic, controlling transactions, workflow logic and every activity that is related to the application so it could be called Application Service Layer. The layer exploits repositories to perform its job.
Unit of Work
Maintains a list of objects affected by a business transaction and coordinates the writing out of changes and the resolution of concurrency problems.
The main purpose of Unit of Work is to manage transactions in a way that repositories are free from this concern. Repositories can be part of a transaction, but being ignorant about it.
Repository
Mediates between the domain and data mapping layers using a collection-like interface for accessing domain objects.
Repositories are components that encapsulate the logic required to access data sources. They decouple data access logic and technology from domain logic.
Normally every Aggregate Domain Model has a repository. Martin Fowler describes Aggregate or Aggregate root as below:
Aggregate is a pattern in Domain-Driven Design. A DDD aggregate is a cluster of domain objects that can be treated as a single unit.
This is important that every aggregate in the domain model should have one repository which maintains transnational consistency between all the objects within the aggregate.
I tend to think about repositories - as Martin Fowler describes it - as a mediator between domain and data mapper, but what is Data Mapper?
A layer of Mappers that moves data between objects and a database while keeping them independent of each other and the mapper itself.
Inside the repository, data mapper performs its job to retrieve and persist data to data source(s).
Data sources are mostly somewhere outside of your application like SqlServer, Oracle, MongoDB and so on, they may have different mechanisms to structure data. Applications need a mechanism to communicate with these external data sources, this mechanism is called Data Mapper. It is like a bridge between the application and the data source. Objects and data sources have different mechanisms for structuring data. For instance, Relational databases do not support inheritance or collections. Data mapper is responsible for transferring data between objects and data sources in a way that these concepts are ignorant about each other.
Repository and Transactions
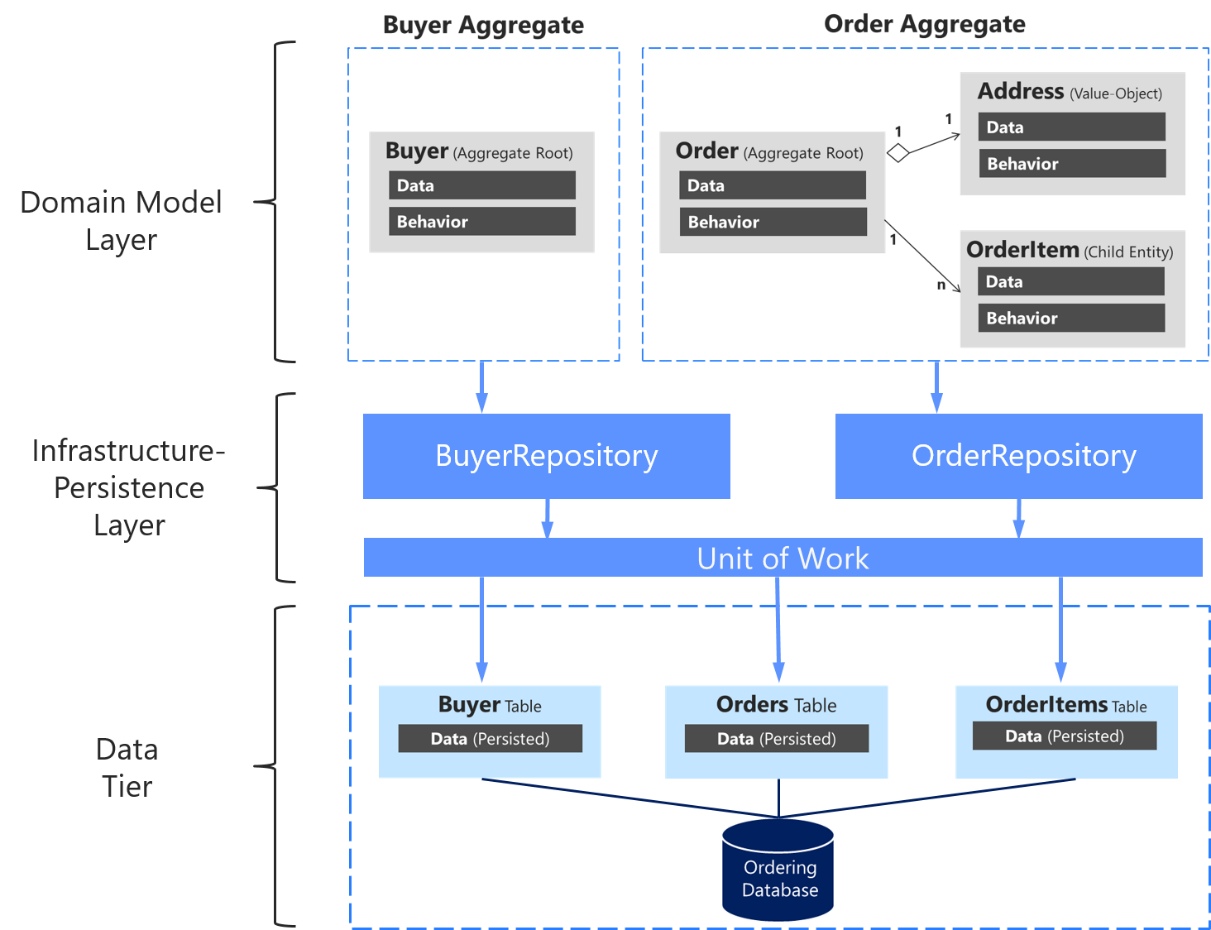
The above diagram shows that the Unit of Work manages transactions for two repositories which one of them is an aggregate repository.
Service Layer uses repositories to perform its operations. Transaction over repositories should be handled by Service Layer via Unit of Work.
Repository design
Repositories should be defined based on its consumer needs which is based on use-cases. Having general and unified methods in a repository is not a good idea because not all aggregates have the same needs, it is also possible that general repositories have leaky abstraction. It is always tempting to design repositories for the sake of code-reuse, but this kind of code-reuse pollutes repositories with useless methods that throws the
NotImplementedException. For instance, imagine that we have a General Repository - in C# -like this:
public interface IRepository<TAggregate, TId>
{
IEnumerable<TAggregate> FindAllMatching(Expression<Func<T, bool>> query);
IEnumerable<TAggregate> FindAllMatching(string query);
TAggregate FindBy(TId id);
void Add(TAggregate aggregate);
void Remove(TAggregate aggregate);
}
Well, the definition is a good idea for code-reuse ,but a bad one for repository. The first problem is that some aggregates may be read-only, so Add and Remove methods are useless and the implementation must throws the NotImplementedException. The second problem is that FindAllMatching(string query) has leaky abstraction, the method is open to extension and you have no control to query optimization and fetching strategies.
Can Repository be replaced with ORM?
Domain models are more than a Plain Object that ORMs use to store data. They can not be replaced.
Robert C Martin said:
The biggest problem with ORM’s is that they don’t really map O to R. Tables are not objects. They never were; and never will be.
The relations between domain models - mostly - is different from relations between database objects. The main purpose of domain models is supporting use-cases not the structure of database objects.
If you are using Domain Driven Design (DDD) in your project, you meant to use Repository. It makes you follow principle and have clean code, replacing Repository with ORM should be avoided.
Meaningful contract
Repository is not a CRUD interface, it should not be designed with data-storage’s vocabulary. It is something that domain experts can understand for the sake of Ubiquitous Language. The repository contract should be specific in the way that developers understand the purpose of a method without exploring the code. A repository comes from the need of use-cases, so it should be specific and understandable.
Let’s look at two versions of ICustomerRepository. Which one is more understandable and specific? Obviously the second version is much better than the first one.
public interface ICustomerRepository
{
Customer GetById(int id);
IReadOnlyList<Customer> GetAll(Expression<Func<Customer, bool>> query);
void Insert(Customer customer);
}
public interface ICustomerRepository: IRepository
{
Customer FindById(int id);
IReadOnlyList<Customer> FindByLastName(string lastName);
IReadOnlyList<Customer> FindByGender(Gernder gender);
void AddNewCustomer(Customer customer);
}
The IRepository is a Marker Interface that provides run-time type information about object.
Repository and Specification Pattern
The central idea of Specification is to separate the statement of how to match a candidate, from the candidate object that it is matched against. As well as its usefulness in selection.
Imagine that you have a use-case that needs to select a subset of objects based on some criteria. If you want to be specific in a repository - based on meaningful contract - the repository’s method will be too complicated. In this situation Specification Pattern can be helpful, it decouples the design of requirements and allows clear and declarative system definitions.
The Specification implementation in C# could be based on interface below:
public interface ISpecification<T>
{
bool IsSatisfiedBy(T candidate);
ISpecification<T> And(ISpecification<T> other);
ISpecification<T> AndNot(ISpecification<T> other);
ISpecification<T> Or(ISpecification<T> other);
ISpecification<T> OrNot(ISpecification<T> other);
ISpecification<T> Not();
}
public abstract class Specification<T> : ISpecification<T> {
...
}
public interface ICustomerRepository
{
public IReadOnlyList<Customer> Find(ISpecification<Customer> specification);
}
public class CustomerRepository : ICustomerRepository {
...
}
As you can see the main pillar of the pattern is bool IsSatisfiedBy(T candidate) that applies the condition to the collection. The rest methods are for composition.
public class FineByCardTypeSpecification : Specification<Customer> {
...
}
public class FineByEmailSpecification : Specification<Customer> {
...
}
public class FineByGenderSpecification : Specification<Customer> {
...
}
public class FineByIdentitySpecification : Specification<Customer> {
...
}
public class FineByLastNameSpecification : Specification<Customer> {
...
}
var emailSpec = new FineByEmailSpecification("person@example.com");
var cardTypeSpecification = new FineByCardTypeSpecification(CardTypes.Visa);
var genderSpecification = new FineByGenderSpecification(Gender.Male);
var customerRepository = new CustomerRepository();
var firstResult = customerRepository.Find(emailSpec.And(genderSpecification));
var secondResult = customerRepository.Find(cardTypeSpecification);
General Repository and DAO
General Repositories tend to be table-centric which means they are an abstraction of data storage structure and concepts. Data Access Object (DAO) has the same definition. In my opinion there is no difference between General Repository and DAO. Sometimes it is considered to be an anti-pattern which I believe, it is half true. In the context of Domain Driven Design, Repository must be specific and has a contract, so General Repository should not be used, but not all applications must follow DDD principles, they can use General Repository to achieve their goals. Thus, General Repositories could be good in some situations and bad one when the Domain Model is used.
Summary
Repository Design Pattern helps an application to persist Domain Model, it is closely related to it and should be specific and follows the contract. To perform a use-case, Application Service Layer exploits Repository and Unit of Work. To have a better Repository, implementing a Specification Pattern could be helpful. General Repository is like DAO and could be helpful if the Domain Model is not used.